Idea Validation: Problem, Market demand, Product
Concierge
Personally deliver your service to test product satisfaction
How: Be upfront about the manual work involved in your product or service and deliver it as a highly customized service to select customers instead of faking a working product like you would with a Wizard of Oz experiment.
Why: Running through your process manually reveals other aspects of the customer experience that can prove valuable later on.
A Concierge MVP is a manual, high-touch prototype in which you personally deliver the service to early users to validate demand before building automation.
What is a Concierge MVP?
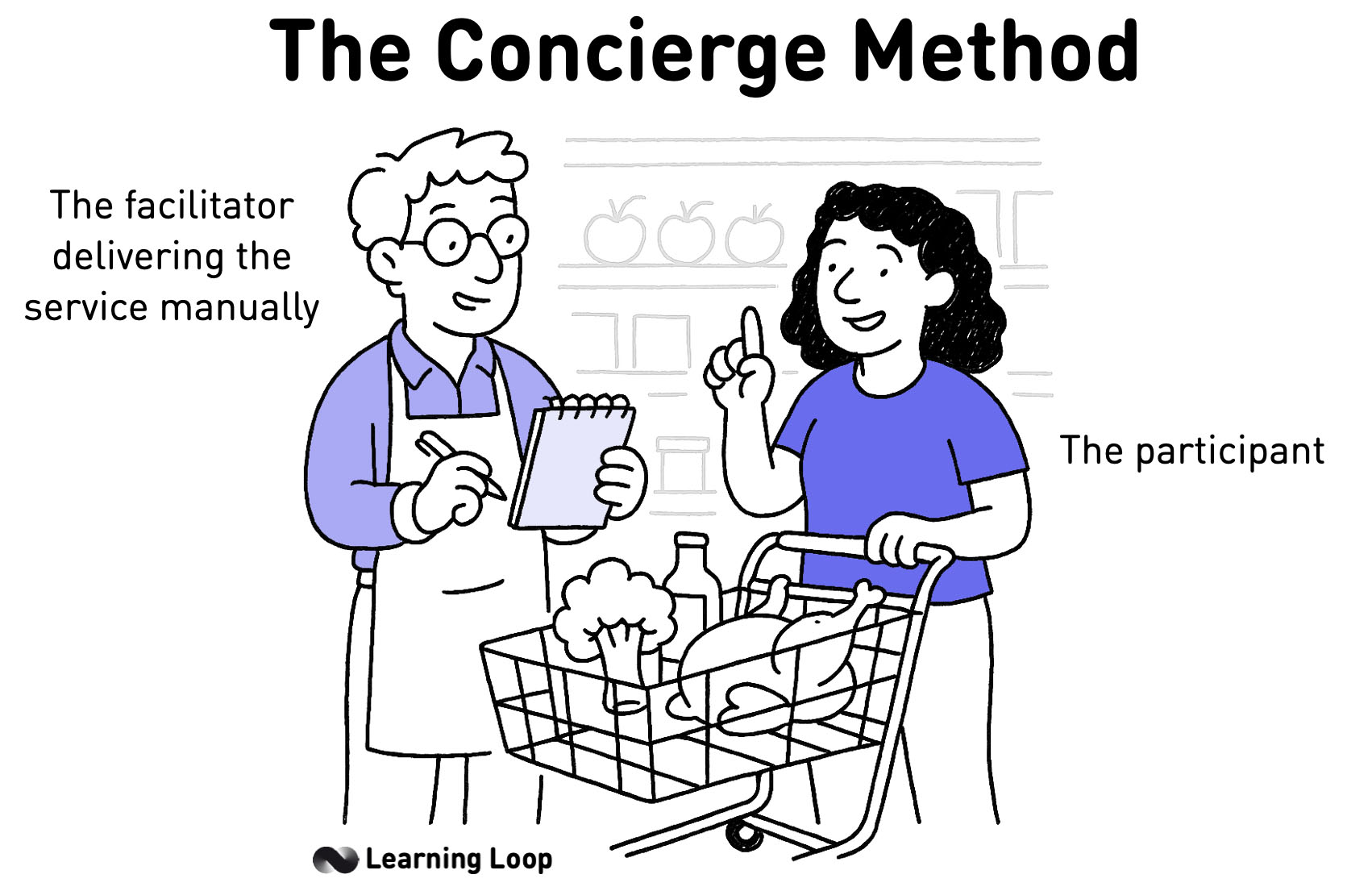
Replacing complicated automations with human power
When contemplating your final product, it is often full of bells and whistles that give users smooth onboarding, smart recommendations, and retention through elaborate email sequences. Even though this is attractive, there is no proof at the start that users want any of it.
A practical way to learn whether your ideal product is relevant is to remove the niceties and rely on human effort—a Concierge MVP. For another low-code approach, compare it with a Wizard of Oz test, where the manual work is hidden from the user.
By replacing automated components with people, every customer receives near-perfect treatment. Skipping code allows you to collect feedback immediately and puts you in direct contact with early users. You will discover what customers need and whether they value what you offer. You will also see the questions they raise and which answers move them forward.
Conducting everything by hand gives you firsthand knowledge of the effort needed to deliver the final product.
Concierge MVP vs Wizard of Oz: Key Differences
Before deciding between these two prototypes, it helps to see their core characteristics side by side. The table below summarises the practical distinctions that matter for planning.
| Topic | Concierge MVP | Wizard of Oz |
|---|---|---|
| Who delivers the value | You or your team interact with the user openly. | A hidden human performs tasks behind a user interface that looks automated. |
| User awareness | Users know humans are involved. | Users assume they are using finished software. |
| Primary goal | Validate demand and learn pains through direct contact. | Test interface expectations and workflow without building the backend. |
| Suitable for | Early-stage discovery, service concepts, B2B offerings. | UI/UX validation, consumer apps where real-time response matters. |
| Scalability | Low; effort grows linearly with users. | Low; but easier to swap in automation module-by-module. |
These contrasts show when each method is appropriate. If direct conversation is needed, choose a Concierge MVP; if interface behaviour is the unknown, consider a Wizard of Oz test.
When to choose a Concierge Test
Doing something that doesn’t scale
As you might expect, Concierge MVPs rarely scale in the long run. That is acceptable. The objective is to test before you build. Once you have thousands of users, you can address scaling—if you never reach that point, you save the effort.
“Do things that don’t scale” – Paul Graham
Why unscalable work matters (Paul Graham principles)
Below are the core ideas from Paul Graham’s essay, each of which underpins a concierge experiment:
- Recruit users one by one. Founders should personally invite and onboard the first users instead of waiting for self-serve sign-ups.
- Delight early adopters. Provide hand-crafted support and extra effort that large companies can’t match, turning users into advocates.
- Keep the market narrow. Focus on a tightly defined segment (e.g., one campus or one persona) until you reach a small critical mass.
- Be the software. Perform tasks manually behind the interface until it is obvious what deserves automation.
- Accept small initial numbers. A 10 % weekly growth rate compounds if you start measuring early.
- Avoid big launches and premature partnerships. Early growth comes from direct engagement, not press releases.
These principles justify the hands-on nature of a Concierge MVP and show why doing unscalable work accelerates early learning.
When to run a Concierge MVP (decision checklist)
Use the checklist below to decide if a concierge test is the right next step:
- You need direct contact to uncover pains, language, and decision triggers.
- You are unsure which part of the solution matters most.
- You have limited engineering capacity and need evidence before committing code.
- The workflow involves complex offline steps that are hard to simulate.
- You want evidence before a small-scale fake-door test or Wizard of Oz follow-up.
Running a Concierge MVP under these conditions maximises learning while keeping risk—and cost—low.
Step-by-Step: How to run a Concierge experiment
The sequence below covers the essential steps to run a concierge prototype in a small scope and capture useful learning.
-
Define the core user outcome.
State the single result you will deliver manually (e.g., “deliver a weekly meal plan”). -
Recruit a small, precise cohort.
Identify 5–10 target users who match your ideal profile. -
Set expectations.
Tell users that you will provide a high-touch, human-driven service for a limited time. -
Deliver the service manually.
Schedule calls, send emails, or meet in person. Record every request and action. -
Capture data and observations.
Track time spent, user reactions, willingness to pay, and drop-off points. -
Debrief after each session.
Note friction, repeated tasks, and any features users try to “pull” from you. -
Synthesize findings.
Convert raw notes into insights about must-have features, pricing, and next steps.
Following these steps keeps the experiment structured and allows clear learning without overextending resources.
Identifying next steps after a Concierge Test
After finishing the experiment, work through the following checklist to decide what comes next based on evidence rather than intuition.
- Demand signal: Did users return or refer others?
- Value metric: Could you charge a realistic price?
- Process repeatability: Which steps were identical across users?
- Automation candidates: Which tasks consumed > 30 % of your effort?
- Risk assessment: What assumptions remain untested?
- Roadmap decision:
- Build a small automated feature.
- Run a Wizard of Oz follow-up.
- Pivot or stop if demand is weak.
Using the checklist helps convert observations into a concrete plan and prevents drifting into development without clear justification.
Metrics to track and when to automate
Meaningful measurement keeps the experiment grounded in evidence and shows when manual work becomes a bottleneck. Track both outcome metrics (demand and value) and process metrics (effort and quality). Review them weekly and log changes in a simple spreadsheet or analytics dashboard.
| Metric | How to calculate | Why it matters | Typical threshold for first automation |
|---|---|---|---|
| Conversion rate from sign-up → first activation | activated_users / sign-ups |
Confirms initial interest and early value. | ≥ 20 % suggests demand worth deeper validation. |
| Repeat usage | users_with_2+ activations / activated_users |
Indicates ongoing value. | ≥ 40 % repeat within 30 days. |
| Time per activation | total_manual_minutes / activations |
Reveals cost drivers. | > 30 min per activation signals need to streamline. |
| Manual steps repeated ≥ 3 × | Count identical actions done across users | Highlights opportunities to script or template. | Any step repeated for 80 % of users. |
| Net Promoter Score (NPS) | promoters − detractors |
Gauges satisfaction. | > 30 means experience is strong enough to merit automation. |
| Revenue per user (ARPU) | total_revenue / activated_users |
Validates pricing assumptions. | ≥ target ARPU required for viable unit economics. |
| Customer acquisition cost (CAC) | marketing + sales spend / new users |
Shows payback feasibility. | CAC ≤ 35 % of projected LTV. |
| Manual error rate | issues requiring rework / activations |
Captures quality risks that grow with scale. | > 5 % errors justify tooling or checks. |
Interpretation and next steps
- Sustained demand. Strong conversion and repeat usage show the product solves a real problem, making further investment reasonable.
- Rising effort. If time per activation or error rate climbs while demand stays flat, automate the single most time-consuming step first.
- Positive economics. When ARPU minus CAC stays positive for two cycles and NPS is stable, lightweight internal tooling is justified.
- Learning plateau. If key metrics stop changing despite experiments, automate low-value chores to free time for new tests rather than scaling prematurely.
Regularly plotting these metrics over time guards against premature scaling and highlights which tasks deserve automation first.
Getting it right - common mistakes and how to fix them
Several issues appear repeatedly when teams run concierge tests; the table lists them with simple fixes.
| Pitfall | Mitigation |
|---|---|
| Serving too many users too soon | Limit cohort size; close sign-ups when bandwidth is full. |
| Over-engineering tracking sheets | Start with a simple spreadsheet; refine later. |
| Ignoring negative feedback | Schedule a debrief after every session and log objections. |
| Automating before demand is clear | Wait for repeat usage and willingness-to-pay signals. |
| Failing to inform users of changes | Send concise updates when the process or timeline changes. |
Addressing these pitfalls early keeps effort focused on learning instead of rework.
Frequently Asked Questions
What is a Concierge MVP?
A Concierge MVP is a prototype where humans deliver the product or service manually to test demand before investing in automation.
How is a Concierge Test different from a Wizard of Oz prototype?
In a Concierge Test the user knows humans are involved; in a Wizard of Oz the human effort is hidden behind an interface that appears complete.
When should I pick a Concierge MVP?
Choose it when direct contact with users is essential to learn their pains, when engineering resources are limited, or when the service idea involves complex offline work.
Does a Concierge MVP scale?
It does not scale by design. It is a temporary method for learning before committing to code or process automation.
What metrics decide the next steps after a Concierge Test?
Look at repeat usage, willingness to pay, manual effort per user, and qualitative feedback. If these indicators are positive, automate the highest-effort tasks next.
Real life Concierge examples
Rent the Runway
Rent the Runway tested its online dress rental business model by providing an in-person service to female college students where they could try a dress on before renting it. This helped validate the hypothesis that women would rent dresses and proved they would pay money for the service as well.
Source: Building a Minimum Viable Product? You’re Probably Doing it Wrong
Get Maid
Get Maid, an app for booking home cleaning, validated their concepts by first product by creating a skinny front-end app that would merely send the founders a text message. When receiving a message, they would check to see who was available and then text the customer that the appointment was confirmed once they found a maid.
Food on the Table
When Food on the Table first started, CEO Manuel Rosse didn’t have a website, but sold his service for $10 a month in person to shoppers. As he got his first customers, he generated the recipes and grocery lists his service promised in person, while accompanying them around the store.
Source: Learn about Lean Startup

A collection of 60 product experiments that will validate your idea in a matter of days, not months. They are regularly used by product builders at companies like Google, Facebook, Dropbox, and Amazon.
Get your deck!Related plays
- Concierge vs. Wizard of Oz Test - what's the difference by Tristan Kromer
- Validating Product Ideas Through Lean User Research by Tomer Sharon
- Building a Minimum Viable Product? You’re Probably Doing it Wrong by N. Taylor Thompson
- Learn about Lean Startup by Patrick O'Malley
- The Real Startup book - Concierge by Tristan Kromer, et. al.
- Do things that don't scale by Paul Graham